标准库的函数
sort()
std::sort() 通常是快速排序或其变种(如内省排序、三路快速排序等),具体的实现会因编译器和标准库的不同而有所差异。以下是快速排序的几种简单优化方法,一些编译器和标准库可能用了以下方法:
- 减小递归深度:
std::sort()会递归地对这两个部分分别应用相同的排序算法,直到每个部分的大小小于某个阈值(通常是几个元素)。一旦达到这个阈值,std::sort()会切换到其他排序算法,如插入排序,以减少递归深度和额外的递归开销。
又如内省排序将快速排序的最大递归深度限制为 ,超过限制时就转换为堆排序。这样既保留了快速排序内存访问的局部性,又可以防止快速排序在某些情况下性能退化为 。 - 三数取中:选择枢轴时,
std::sort()通常会选择数组或容器的三个元素中的中间值,而不是单纯选择第一个或最后一个元素。这可以减少最坏情况的发生概率(逆序序列),提高算法在最坏情况下的时间复杂度。 - 尾递归优化:如果递归步骤中较小的部分已经有序,那么
std::sort()会优化以避免对这些部分进行不必要的排序。 - 类似三路快速排序:每趟排序后,将与分界元素相等的元素聚集在分界元素周围。排序有多个重复值的数组时,效率远高于原始快速排序,最佳时间复杂度为 。
当然快速排序还能进一步优化,直接使用 std::sort() 无法通过洛谷 P1177 【模板】排序,这道题需要手搓快速排序算法。
#include <algorithm>
#include <vector>
int main() {
std::vector<int> vec = {3, 1, 4, 1, 5, 9, 2, 6};
std::sort(vec.begin(), vec.end());
// vec = {1, 1, 2, 3, 4, 5, 6, 9}
return 0;
}
stable_sort()
std::stable_sort() 函数也用于对给定范围内的元素进行排序,但它保证排序是稳定的。
它通常使用归并排序算法。
#include <algorithm>
#include <vector>
int main() {
std::vector<int> vec = {3, 1, 4, 1, 5, 9, 2, 6};
std::stable_sort(vec.begin(), vec.end());
// vec = {1, 1, 2, 3, 4, 5, 6, 9}
return 0;
}
qsort()
与C++标准库的 std::sort() 函数不同,qsort() 并不会根据数据特性来选择最佳的排序算法。它使用的是快速排序的一种简化版本,不具备自适应性和优化特性。因此,qsort() 并不会根据数据特性动态选择排序算法。
C中,使用 qsort() 函数时,用户必须要提供一个比较函数来定义排序规则。该比较函数必须符合 qsort() 函数指定的格式,以便 qsort() 能够正确地比较数组中的元素。用户可以通过提供不同的比较函数来改变排序的规则,但是选择的排序算法仍然是快速排序。
#include <stdio.h>
#include <stdlib.h>
int compare_function(const void *a, const void *b) {
int num1 = *((int *)a), num2 = *((int *)b);
if (num1 < num2)
return -1;
else if (num1 > num2)
return 1;
else
return 0;
}
int main() {
int arr[] = {3, 1, 4, 1, 5, 9, 2, 6};
int n = sizeof(arr) / sizeof(arr[0]);
qsort(arr, n, sizeof(int), compare_function);
for (int i = 0; i < n; ++i) {
printf("%d ", arr[i]);
}
printf("\n");
return 0;
}
Tim 排序
Tim排序是一种结合了归并排序和插入排序的稳定排序算法,由Tim Peters于2002年提出。它的性能在实际应用中表现良好,特别是在处理大型数据集时。Tim排序的主要思想是通过先使用插入排序对小规模的子数组进行排序,然后再使用归并排序对已经部分有序的子数组进行合并。
适用
Tim排序在以下情况下通常更好:
-
大规模数据集:Tim排序在处理大规模数据集时性能较好,因为它能够充分利用归并排序的高效性能,同时通过插入排序的局部性质,对小规模子数组进行快速排序。
-
部分有序的数据集:当待排序的数据集部分有序时,Tim排序的性能可能比其他排序算法更好。这是因为Tim排序采用了归并排序,在合并阶段能够有效地利用已经有序的子数组,减少不必要的比较和交换操作。
-
需要稳定性:Tim排序是一种稳定排序算法,可以保持相等元素的相对位置不变。在需要保持稳定性的情况下,Tim排序是一个很好的选择。
但是,Tim排序可能不如其他排序算法在以下情况下:
-
小规模数据集:由于Tim排序在小规模数据集上采用插入排序,但插入排序对于小规模数据集的效率并不一定比快速排序等算法更高。因此,在处理小规模数据集时,可能有其他算法更加合适。
-
内存占用较大:Tim排序需要额外的空间来存储中间结果,尤其是在归并阶段。对于内存有限的情况下,可能会导致内存消耗较大,不适合使用Tim排序。
-
对排序稳定性要求不高:如果对排序的稳定性要求不高,可以接受部分相等元素的相对位置被改变,那么可能会选择其他性能更好的排序算法,如快速排序或堆排序。
分析
- 插入排序阈值选择:
Tim排序首先确定一个阈值,通常在32到64之间。这个阈值的作用是确定何时切换到插入排序。如果待排序数组的大小小于这个阈值,就会采用插入排序来处理。 - 分区:
将待排序的数组分成若干个小块(称为run),每个小块的大小不超过插入排序的阈值。通常,使用插入排序对每个小块进行排序,从而得到一些已经部分有序的run。 - 归并排序:
使用归并排序将已经排序好的run逐步合并,直到整个数组排序完成。归并的过程是基于稳定的归并操作,确保了排序的稳定性。 - 合并策略:
Tim排序使用一种特殊的合并策略,称为归并树(merge tree)或Tim树。在这个合并策略中,首先对相邻的run进行归并,然后逐级向上合并,直到整个数组都被合并为止。这种策略可以有效地利用CPU缓存,从而提高了排序的性能。 - 优化:
Tim排序通常会采用一些优化技巧,比如对已经有序的run进行标记,以减少不必要的归并操作。此外,还可以通过多线程等方法加速排序过程。
总的来说,Tim排序通过结合插入排序和归并排序的优点,以及优化归并过程,实现了高效的稳定排序算法。它的性能在大部分情况下都比较优秀,并且对于大规模数据集的排序表现尤为突出。
代码实现
#include <bits/stdc++.h>
using namespace std;
const int INSERTION_SORT_THRESHOLD = 64;
void insertionSort(vector<int>& arr, int left, int right) {
for (int i = left + 1; i <= right; ++i) {
int key = arr[i];
int j = i - 1;
while (j >= left && arr[j] > key) {
arr[j + 1] = arr[j];
--j;
}
arr[j + 1] = key;
}
}
void merge(vector<int>& arr, int left, int mid, int right) {
int n1 = mid - left + 1;
int n2 = right - mid;
vector<int> L(n1), R(n2);
for (int i = 0; i < n1; ++i)
L[i] = arr[left + i];
for (int j = 0; j < n2; ++j)
R[j] = arr[mid + 1 + j];
int i = 0, j = 0, k = left;
while (i < n1 && j < n2) {
if (L[i] <= R[j]) {
arr[k] = L[i];
++i;
} else {
arr[k] = R[j];
++j;
}
++k;
}
while (i < n1) {
arr[k] = L[i];
++i;
++k;
}
while (j < n2) {
arr[k] = R[j];
++j;
++k;
}
}
void timSort(vector<int>& arr, int left, int right) {
if (right - left + 1 <= INSERTION_SORT_THRESHOLD) {
insertionSort(arr, left, right);
return;
}
int mid = left + (right - left) / 2;
timSort(arr, left, mid);
timSort(arr, mid + 1, right);
merge(arr, left, mid, right);
}
void timSort(vector<int>& arr) {
timSort(arr, 0, arr.size() - 1);
}
int main() {
vector<int> arr = {3, 5, 3, 8, 6, 2, 7, 1, 4};
cout << "Original Array:" << endl;
for (int num : arr)
cout << num << " ";
cout << endl;
timSort(arr);
cout << "Sorted Array:" << endl;
for (int num : arr)
cout << num << " ";
cout << endl;
return 0;
}
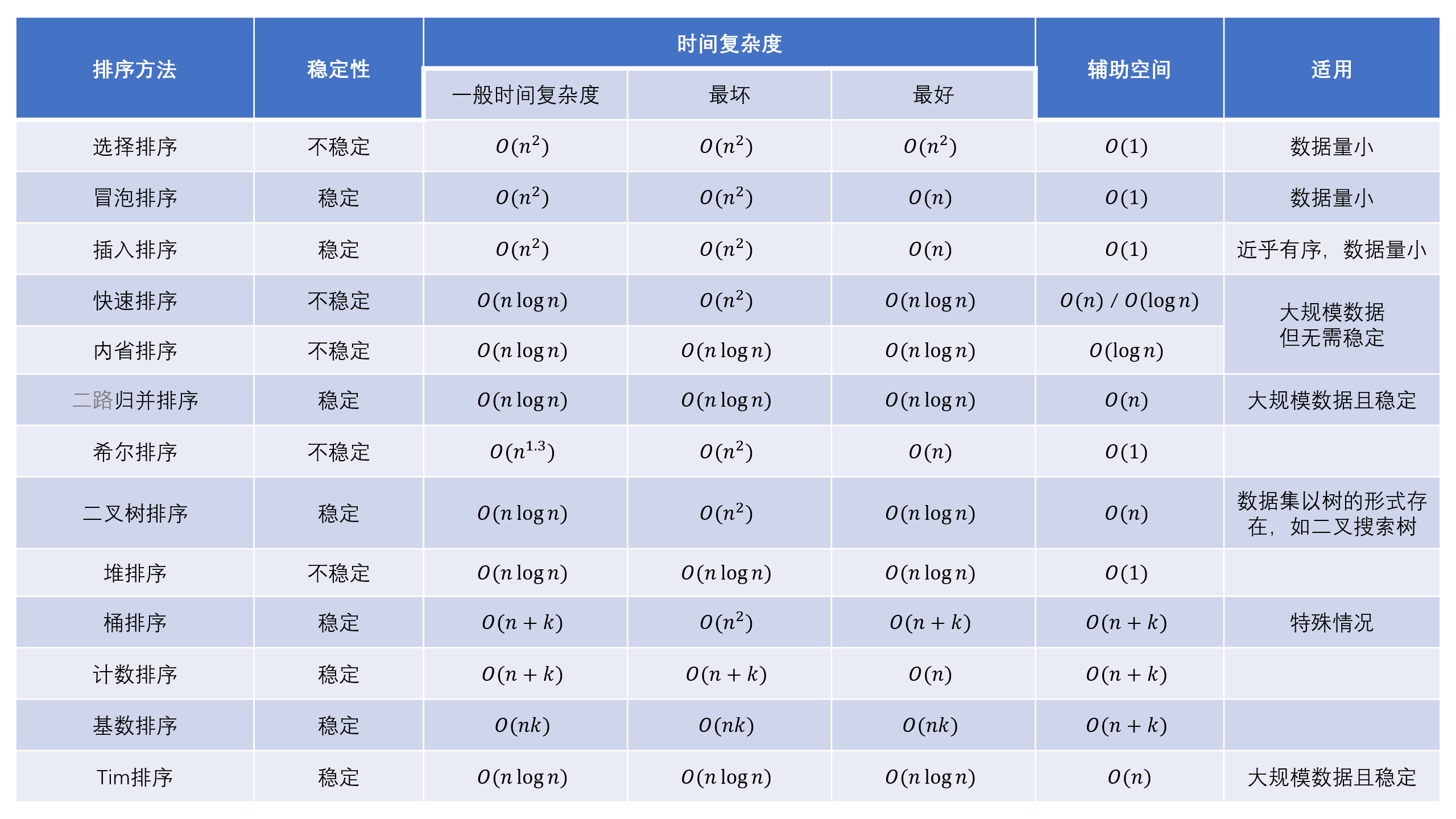
排序总结
© Nail_ 2024 from 124.220.68.222
*Copyright © Nail_ 2024 All rights reserved. This image is the property of Nail_. Reproduction of this image is permitted with proper attribution to Nail_ as the source, along with this copyright notice. Unauthorized distribution, including failure to provide proper attribution and copyright notice, is strictly prohibited.
举例
洛谷 P3366 【模板】最小生成树
使用插入排序(46-53行标注处)有三个测试点TLE,使用C++标准库快速排序(16-18, 55行标注处)全部AC。
#include <bits/stdc++.h> using namespace std; #define ulli unsigned long long int #define lli long long int //const int MAX_npoint=20; const int MAX_npoint=5003+9; const int MAX_nline=200005+9; int datum[MAX_npoint][MAX_npoint]; int father[MAX_npoint]; struct node{ //手搓从小到大放[^1] int length; int a,b; }; vector<node> shortest; bool cmp(node a,node b){ return a.length<b.length; } int ffindfa(int fn){ if(father[fn]==fn) return fn; else{ return father[fn]=ffindfa(father[fn]); } } int main(){ int npoint,nline; scanf("%d %d",&npoint,&nline); int tempia,tempib,tempic; for(int i=1;i<=nline;i++){ scanf("%d %d %d",&tempia,&tempib,&tempic); int isChange=datum[tempib][tempia]; if(datum[tempia][tempib]==0) datum[tempia][tempib]=datum[tempib][tempia]=tempic; else datum[tempia][tempib]=datum[tempib][tempia]=min(datum[tempib][tempia],tempic); node tempnode; tempnode.length=tempic; tempnode.a=tempia; tempnode.b=tempib; if(isChange!=datum[tempib][tempia]){ // if(shortest.size()==0) // shortest.push_back(tempnode); // else{ // //[^1]: 插入排序 // ulli j; // for(j=0;j<shortest.size();j++) // if(shortest[j].length>=tempnode.length) break; // if(j==shortest.size()) // shortest.push_back(tempnode); // else // shortest.insert(shortest.begin()+j,tempnode); // } shortest.push_back(tempnode); } } sort(shortest.begin(),shortest.end(),cmp); for(int i=1;i<=npoint;i++) father[i]=i; int res=0,lineTimes=0; for(ulli i=0;i<shortest.size();i++){ int pa=shortest[i].a,pb=shortest[i].b; int fatherpa=ffindfa(pa),fatherpb=ffindfa(pb); if(fatherpa!=fatherpb){ father[fatherpa]=fatherpb; res+=shortest[i].length; lineTimes++; } } if(res==0||lineTimes!=(npoint-1)) printf("orz"); else printf("%d",res); return 0; }